https://dropithere.netlify.app/text/2YHoFbMDK1H3LDAKZCN3
http://ningspruz7.tech/button2901
Graph · Complex network · Contagion Small-world · Scale-free · Community structure · Percolation · Evolution · Controllability · Graph drawing · Social capital · Link analysis · Optimization Reciprocity · Closure · Homophily Transitivity · Preferential attachment Balance · Network effect · Influence
Information · Telecommunication Social · Biological · Neural Interdependent · Semantic Random · Dependency · Flow
Vertex · Edge · Component Directed · Multigraph · Bipartite Weighted · Hypergraph · Random Cycle · Loop · Path Neighborhood · Clique · Complete · Cut Data structure · Adjacency list & matrix Incidence list & matrix
Centrality · Degree · Betweenness Closeness · PageRank · Motif Clustering · Degree distribution · Assortativity · Distance · Modularity
Random · Erdős–Rényi Barabási–Albert · Watts–Strogatz ERGM · Epidemic · Hierarchical
Graph theory · Network theory
Network science is an interdisciplinary academic field which studies complex networks such as telecommunication networks, computer networks, biological networks, cognitive and semantic networks, and social networks. The field draws on theories and methods including graph theory from mathematics, statistical mechanics from physics, data mining and information visualization from computer science, inferential modeling from statistics, and social structure from sociology. The United States National Research Council defines network science as "the study of network representations of physical, biological, and social phenomena leading to predictive models of these phenomena."
[1]
The study of networks has emerged in diverse disciplines as a means of analyzing complex relational data. The earliest known paper in this field is the famous Seven Bridges of Königsberg written by Leonhard Euler in 1736. Euler's mathematical description of vertices and edges was the foundation of graph theory, a branch of mathematics that studies the properties of pairwise relations in a network structure. The field of graph theory continued to develop and found applications in chemistry (Sylvester, 1878).
In the 1930s Jacob Moreno, a psychologist in the Gestalt tradition, arrived in the United States. He developed the sociogram and presented it to the public in April 1933 at a convention of medical scholars. Moreno claimed that "before the advent of sociometry no one knew what the interpersonal structure of a group 'precisely' looked like (Moreno, 1953). The sociogram was a representation of the social structure of a group of elementary school students. The boys were friends of boys and the girls were friends of girls with the exception of one boy who said he liked a single girl. The feeling was not reciprocated. This network representation of social structure was found so intriguing that it was printed in The New York Times (April 3, 1933, page 17). The sociogram has found many applications and has grown into the field of social network analysis.
Probabilistic theory in network science developed as an off-shoot of graph theory with Paul Erdős and Alfréd
Rényi's eight famous papers on random graphs. For social networks the exponential random graph model or p* is a notational framework used to represent the probability space of a tie occurring in a social network. An alternate approach to network probability structures is the network probability matrix, which models the probability of edges occurring in a network, based on the historic presence or absence of the edge in a sample of networks.
In 1998, David Krackhardt and Kathleen Carley introduced the idea of a meta-network with the PCANS Model. They suggest that "all organizations are structured along these three domains, Individuals, Tasks, and Resources". Their paper introduced the concept that networks occur across multiple domains and that they are interrelated. This field has grown into another sub-discipline of network science called dynamic network analysis.
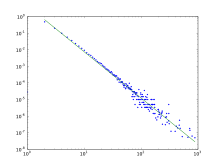
More recently other network science efforts have focused on mathematically describing different network topologies. Duncan Watts reconciled empirical data on networks with mathematical representation, describing the small-world network. Albert-László Barabási and Reka Albert developed the scale-free network which is a loosely defined network topology that contains hub vertices with many connections, that grow in a way to maintain a constant ratio in the number of the connections versus all other nodes. Although many networks, such as the internet, appear to maintain this aspect, other networks have long tailed distributions of nodes that only approximate scale free ratios.
The U.S. military first became interested in network-centric warfare as an operational concept based on network science in 1996. John A. Parmentola, the U.S. Army Director for Research and Laboratory Management, proposed to the Army’s Board on Science and Technology (BAST) on December 1, 2003 that Network Science become a new Army research area. The BAST, the Division on Engineering and Physical Sciences for the National Research Council (NRC) of the National Academies, serves as a convening authority for the discussion of science and technology issues of importance to the Army and oversees independent Army-related studies conducted by the National Academies. The BAST conducted a study to find out whether identifying and funding a new field of investigation in basic research, Network Science, could help close the gap between what is needed to realize Network-Centric Operations and the current primitive state of fundamental knowledge of networks.
As a result, the BAST issued the NRC study in 2005 titled Network Science (referenced above) that defined a new field of basic research in Network Science for the Army. Based on the findings and recommendations of that study and the subsequent 2007 NRC report titled Strategy for an Army Center for Network Science, Technology, and Experimentation, Army basic research resources were redirected to initiate a new basic research program in Network Science. To build a new theoretical foundation for complex networks, some of the key Network Science research efforts now ongoing in Army laboratories address:
As initiated in 2004 by Frederick I. Moxley with support he solicited from David S. Alberts, the Department of Defense helped to establish the first Network Science Center in conjunction with the U.S. Army at the United States Military Academy (USMA). Under the tutelage of Dr. Moxley and the faculty of the USMA, the first interdisciplinary undergraduate courses in Network Science were taught to cadets at West Point. Subsequently, the U.S. Department of Defense has funded numerous research projects in the area of Network Science.
In 2006, the U.S. Army and the United Kingdom (UK) formed the Network and Information Science International Technology Alliance, a collaborative partnership among the Army Research Laboratory, UK Ministry of Defense and a consortium of industries and universities in the U.S. and UK. The goal of the alliance is to perform basic research in support of Network- Centric Operations across the needs of both nations.
In 2009, the U.S. Army formed the Network Science CTA, a collaborative research alliance among the Army Research Laboratory, CERDEC, and a consortium of about 30 industrial R&D labs and universities in the U.S. The goal of the alliance is to develop a deep understanding of the underlying commonalities among intertwined social/cognitive, information, and communications networks, and as a result improve our ability to analyze, predict, design, and influence complex systems interweaving many kinds of networks.
Today, network science is an exciting and growing interdisciplinary field. Scientists from many diverse fields are working together. Network science holds the promise of increasing collaboration across disciplines, by sharing data, algorithms, and software tools.
Often, networks have certain attributes that can be calculated to analyze the properties & characteristics of the network. These network properties often define network models and can be used to analyze how certain models contrast to each other. Many of the definitions for other terms used in network science can be found in Glossary of graph theory.
The density of a network is defined as a ratio of the number of edges to the number of possible edges, given by the binomial coefficient , giving
The size of a network can refer to the number of nodes or, less commonly, the number of edges which can range from (a tree) to (a complete graph).
The degree of a node is the number of edges connected to it. Closely related to the density of a network is the average degree, . In the ER random graph model, we can compute where is the probability of two nodes being connected.
Average path length is calculated by finding the shortest path between all pairs of nodes, adding them up, and then dividing by the total number of pairs. This shows us, on average, the number of steps it takes to get from one member of the network to another.
As another means of measuring network graphs, we can define the diameter of a network as the longest of all the calculated shortest paths in a network. In other words, once the shortest path length from every node to all other nodes is calculated, the diameter is the longest of all the calculated path lengths. The diameter is representative of the linear size of a network.
The clustering coefficient is a measure of an "all-my-friends-know-each-other" property. This is sometimes described as the friends of my friends are my friends. More precisely, the clustering coefficient of a node is the ratio of existing links connecting a node's neighbors to each other to the maximum possible number of such links. The clustering coefficient for the entire network is the average of the clustering coefficients of all the nodes. A high clustering coefficient for a network is another indication of a small world.
The clustering coefficient of the 'th node is
where is the number of neighbours of the 'th node, and is the number of connections between these neighbours. The maximum possible number of connections between neighbors is, of course,
The way in which a network is connected plays a large part into how networks are analyzed and interpreted. Networks are classified in four different categories:
Node centrality can be viewed as a measure of influence or importance in a network model. There exists three main measures of Centrality that are studied in Network Science.
Network models serve as a foundation to understanding interactions within empirical complex networks. Various random graph generation models produce network structures that may be used in comparison to real-world complex networks.
The Erdős–Rényi model, named for Paul Erdős and Alfréd Rényi, is used for generating random graphs in which edges are set between nodes with equal probabilities. It can be used in the probabilistic method to prove the existence of graphs satisfying various properties, or to provide a rigorous definition of what it means for a property to hold for almost all graphs.
To generate an Erdős–Rényi model two parameters must be specified: the number of nodes in the graph generated as and the probability that a link should be formed between any two nodes as . A constant may derived from these two components with the formula .
The Erdős–Rényi model has several interesting characteristics in comparison to other graphs. Because the model is generated without bias to particular nodes, the degree distribution is binomial in nature with regards to the formula: . Also as a result of this characteristic, the clustering coefficient tends to 0. The model tends to form a giant component in situations where <k> > 1 in a process called percolation. The average path length is relatively short in this model and tends to .
The Watts and Strogatz model is a random graph generation model that produces graphs with small-world properties.
An initial lattice structure is used to generate a Watts-Strogatz model. Each node in the network is initially linked to its closest neighbors. Another parameter is specified as the rewiring probability. Each edge has a probability that it will be rewired to the graph as a random edge. The expected number of rewired links in the model is .
As the Watts-Strogatz model begins as non-random lattice structure, it has a very high clustering coefficient along with high average path length. Each rewire is likely to create a shortcut between highly connected clusters. As the rewiring probability increases, the clustering coefficient decreases slower than the average path length. In effect, this allows the average path length of the network to decrease significantly with only slightly decreases in clustering coefficient. Higher values of p force more rewired edges, which in effect makes the Watts-Strogatz model a random network.
The Barabási–Albert model is a random network model used to demonstrate a preferential attachment or a "rich-get-richer" effect. In this model, an edge is most likely to attach to nodes with higher degrees. The network begins with an initial network of m0 nodes. m0 ≥ 2 and the degree of each node in the initial network should be at least 1, otherwise it will always remain disconnected from the rest of the network.
In the BA model, new nodes are added to the network one at a time. Each new node is connected to existing nodes with a probability that is proportional to the number of links that the existing nodes already have. Formally, the probability pi that the new node is connected to node i is[2]
where ki is the degree of node i. Heavily linked nodes ("hubs") tend to quickly accumulate even more links, while nodes with only a few links are unlikely to be chosen as the destination for a new link. The new nodes have a "preference" to attach themselves to the already heavily linked nodes.
The degree distribution resulting from the BA model is scale free, in particular, it is a power law of the form:
Hubs exhibit high betweenness centrality which allows short paths to exist between nodes. As a result the BA model tends to have very short average path lengths. The clustering coefficient of this model also tends to 0. While the diameter, D, of many models including the Erdős Rényi random graph model and several small world networks is proportional to log N, the BA model exhibits D~loglogN (ultr-small word).[4] Note that the average opath length scale with N as the diameter.
Social network analysis examines the structure of relationships between social entities.[5] These entities are often persons, but may also be groups, organizations, nation states, web sites, scholarly publications.
Since the 1970s, the empirical study of networks has played a central role in social science, and many of the mathematical and statistical tools used for studying networks have been first developed in sociology.[6] Amongst many other applications, social network analysis has been used to understand the diffusion of innovations, news and rumors. Similarly, it has been used to examine the spread of both diseases and health-related behaviors. It has also been applied to the study of markets, where it has been used to examine the role of trust in exchange relationships and of social mechanisms in setting prices. Similarly, it has been used to study recruitment into political movements and social organizations. It has also been used to conceptualize scientific disagreements as well as academic prestige. More recently, network analysis (and its close cousin traffic analysis) has gained a significant use in military intelligence, for uncovering insurgent networks of both hierarchical and leaderless nature.[7][8]
With the recent explosion of publicly available high throughput biological data, the analysis of molecular networks has gained significant interest. The type of analysis in this content are closely related to social network analysis, but often focusing on local patterns in the network. For example network motifs are small subgraphs that are over-represented in the network. Activity motifs are similar over-represented patterns in the attributes of nodes and edges in the network that are over represented given the network structure.
Link analysis is a subset of network analysis, exploring associations between objects. An example may be examining the addresses of suspects and victims, the telephone numbers they have dialed and financial transactions that they have partaken in during a given timeframe, and the familial relationships between these subjects as a part of police investigation. Link analysis here provides the crucial relationships and associations between very many objects of different types that are not apparent from isolated pieces of information. Computer-assisted or fully automatic computer-based link analysis is increasingly employed by banks and insurance agencies in fraud detection, by telecommunication operators in telecommunication network analysis, by medical sector in epidemiology and pharmacology, in law enforcement investigations, by search engines for relevance rating (and conversely by the spammers for spamdexing and by business owners for search engine optimization), and everywhere else where relationships between many objects have to be analyzed.
The structural robustness of networks[9] is studied using percolation theory. When a critical fraction of nodes is removed the network becomes fragmented into small clusters. This phenomenon is called percolation[10] and it represents an order-disorder type of phase transition with critical exponents.
The SIR Model is one of the most well known algorithms on predicting the spread of global pandemics within an infectious population.
The formula above describes the "force" of infection fore each susceptible unit in an infectious population, where β is equivalent to the transmission rate of said disease.
To track the change of those susceptible in an infectious population:
Over time, the number of those infected fluctuates by: the specified rate of recovery, represented by but deducted to one over the average infectious period , the numbered of infecious individuals, , and the change in time, .
Whether a population will be overcome by a pandemic, with regards to the SIR model, is dependent on the value of or the "average people infected by an infected individual."
Several Web search ranking algorithms use link-based centrality metrics, including (in order of appearance) Marchiori's Hyper Search, Google's PageRank, Kleinberg's HITS algorithm, the CheiRank and TrustRank algorithms. Link analysis is also conducted in information science and communication science in order to understand and extract information from the structure of collections of web pages. For example the analysis might be of the interlinking between politicians' web sites or blogs.
PageRank works by randomly picking "nodes" or websites and then with a certain probability, "randomly jumping" to other nodes. By randomly jumping to these other nodes, it helps PageRank completely traverse the network as some webpages exist on the periphery and would not as readily be assessed.
Each node, , has a PageRank as defined by the sum of pages that link to times one over the outlinks or "out-degree" of times the "importance" or PageRank of .
As explained above, PageRank enlists random jumps in attempts to assign PageRank to every website on the internet. These random jumps find websites that might not be found during the normal search methodologies such as Breadth-First Search and Depth-First Search.
In an improvement over the aforementioned formula for determining PageRank includes adding these random jump components. Without the random jumps, some pages would receive a PageRank of 0 which would not be good.
The first is , or the probability that a random jump will occur. Contrasting is the "damping factor", or .
Another way of looking at it:
Information about the relative importance of nodes and edges in a graph can be obtained through centrality measures, widely used in disciplines like sociology. Centrality measures are essential when a network analysis has to answer questions such as: "Which nodes in the network should be targeted to ensure that a message or information spreads to all or most nodes in the network?" or conversely, "Which nodes should be targeted to curtail the spread of a disease?". Formally established measures of centrality are degree centrality, closeness centrality, betweenness centrality, eigenvector centrality, and katz centrality. The objective of network analysis generally determines the type of centrality measure(s) to be used.
Content in a complex network can spread via two major methods: conserved spread and non-conserved spread.[11] In conserved spread, the total amount of content that enters a complex network remains constant as it passes through. The model of conserved spread can best be represented by a pitcher containing a fixed amount of water being poured into a series of funnels connected by tubes . Here, the pitcher represents the original source and the water is the content being spread. The funnels and connecting tubing represent the nodes and the connections between nodes, respectively. As the water passes from one funnel into another, the water disappears instantly from the funnel that was previously exposed to the water. In non-conserved spread, the amount of content changes as it enters and passes through a complex network. The model of non-conserved spread can best be represented by a continuously running faucet running through a series of funnels connected by tubes . Here, the amount of water from the original source is infinite Also, any funnels that have been exposed to the water continue to experience the water even as it passes into successive funnels. The non-conserved model is the most suitable for explaining the transmission of most infectious diseases.
In 1927, W. O. Kermack and A. G. McKendrick created a model in which they considered a fixed population with only three compartments, susceptible: , infected, , and recovered, . The compartments used for this model consist of three classes:
The flow of this model may be considered as follows:
Using a fixed population, , Kermack and McKendrick derived the following equations:
Several assumptions were made in the formulation of these equations: First, an individual in the population must be considered as having an equal probability as every other individual of contracting the disease with a rate of , which is considered the contact or infection rate of the disease. Therefore, an infected individual makes contact and is able to transmit the disease with others per unit time and the fraction of contacts by an infected with a susceptible is . The number of new infections in unit time per infective then is , giving the rate of new infections (or those leaving the susceptible category) as (Brauer & Castillo-Chavez, 2001). For the second and third equations, consider the population leaving the susceptible class as equal to the number entering the infected class. However, a number equal to the fraction ( which represents the mean recovery rate, or the mean infective period) of infectives are leaving this class per unit time to enter the removed class. These processes which occur simultaneously are referred to as the Law of Mass Action, a widely accepted idea that the rate of contact between two groups in a population is proportional to the size of each of the groups concerned (Daley & Gani, 2005). Finally, it is assumed that the rate of infection and recovery is much faster than the time scale of births and deaths and therefore, these factors are ignored in this model.
More can be read on this model on the Epidemic model page.
An interdependent network is a system of coupled networks where nodes of one or more networks depend on nodes in other networks. Such dependencies are enhanced by the developments in modern technology. Dependencies may lead to cascading failures between the networks and a relatively small failure can lead to a catastrophic breakdown of the system. Blackouts are a fascinating demonstration of the important role played by the dependencies between networks. A recent study developed a framework to study the cascading failures in an interdependent networks system.[12][13]
Network problems that involve finding an optimal way of doing something are studied under the name of combinatorial optimization. Examples include network flow, shortest path problem, transport problem, transshipment problem, location problem, matching problem, assignment problem, packing problem, routing problem, Critical Path Analysis and PERT (Program Evaluation & Review Technique).
|author1=
|author=
This website is powered by Spruz

 of a network is defined as a ratio of the number of edges
of a network is defined as a ratio of the number of edges 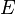 to the number of possible edges, given by the
to the number of possible edges, given by the  , giving
, giving 
 or, less commonly, the number of edges
or, less commonly, the number of edges  (a tree) to
(a tree) to  (a complete graph).
(a complete graph). of a node is the number of edges connected to it. Closely related to the density of a network is the average degree,
of a node is the number of edges connected to it. Closely related to the density of a network is the average degree,  . In the ER random graph model, we can compute
. In the ER random graph model, we can compute  where
where  is the probability of two nodes being connected.
is the probability of two nodes being connected. 'th node is
'th node is
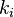 is the number of neighbours of the
is the number of neighbours of the 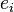 is the number of connections between these neighbours. The maximum possible number of connections between neighbors is, of course,
is the number of connections between these neighbours. The maximum possible number of connections between neighbors is, of course,

 may derived from these two components with the formula
may derived from these two components with the formula  .
. . Also as a result of this characteristic, the clustering coefficient tends to 0. The model tends to form a giant component in situations where <k> > 1 in a process called
. Also as a result of this characteristic, the clustering coefficient tends to 0. The model tends to form a giant component in situations where <k> > 1 in a process called  .
.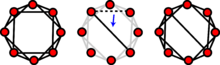
 in this example.
in this example. .
. existing nodes with a probability that is proportional to the number of links that the existing nodes already have. Formally, the probability pi that the new node is connected to node i is
existing nodes with a probability that is proportional to the number of links that the existing nodes already have. Formally, the probability pi that the new node is connected to node i is




 but deducted to one over the average infectious period
but deducted to one over the average infectious period  , the numbered of infecious individuals,
, the numbered of infecious individuals,  , and the change in time,
, and the change in time, 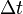 .
.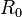 or the "average people infected by an infected individual."
or the "average people infected by an infected individual."
 , has a PageRank as defined by the sum of pages
, has a PageRank as defined by the sum of pages  that link to
that link to 
 , or the probability that a random jump will occur. Contrasting is the "damping factor", or
, or the probability that a random jump will occur. Contrasting is the "damping factor", or  .
.

 , infected,
, infected,  , and recovered,
, and recovered,  . The compartments used for this model consist of three classes:
. The compartments used for this model consist of three classes:
 , Kermack and McKendrick derived the following equations:
, Kermack and McKendrick derived the following equations:


 , which is considered the contact or infection rate of the disease. Therefore, an infected individual makes contact and is able to transmit the disease with
, which is considered the contact or infection rate of the disease. Therefore, an infected individual makes contact and is able to transmit the disease with  others per unit time and the fraction of contacts by an infected with a susceptible is
others per unit time and the fraction of contacts by an infected with a susceptible is  . The number of new infections in unit time per infective then is
. The number of new infections in unit time per infective then is  , giving the rate of new infections (or those leaving the susceptible category) as
, giving the rate of new infections (or those leaving the susceptible category) as  (Brauer & Castillo-Chavez, 2001). For the second and third equations, consider the population leaving the susceptible class as equal to the number entering the infected class. However, a number equal to the fraction (
(Brauer & Castillo-Chavez, 2001). For the second and third equations, consider the population leaving the susceptible class as equal to the number entering the infected class. However, a number equal to the fraction ( which represents the mean recovery rate, or
which represents the mean recovery rate, or  the mean infective period) of infectives are leaving this class per unit time to enter the removed class. These processes which occur simultaneously are referred to as the
the mean infective period) of infectives are leaving this class per unit time to enter the removed class. These processes which occur simultaneously are referred to as the